
Graph for LLM (1)
Published:
Chinese version is in Zhihu 中文版
Graph for LLM (1)
Big thanks to NeurIPS for accepting my paper,
From Sequence to Structure: Uncovering Substructure Reasoning in Transformers — otherwise, there’d be nothing new to post this season.
Honestly, I didn’t expect it to get in. After the rebuttal, everyone’s scores went up — except mine.
But I still wanted to go to the conference, so in August I wrote a workshop paper for Efficient Reasoning,
Uncovering Graph Reasoning in Decoder-only Transformers with Circuit Tracing.
Luckily, both were accepted in the end — huge thanks to the ACs! 🙏 See you in San Diego!🕊️
Neurips paper on understanding pattern extraction task
Both papers explore how decoder-only Transformers trained from scratch handle graph reasoning tasks.
This question isn’t new. People have debated for years why Transformers can perform things like path reasoning, such as shortest-path prediction.
Some argue Transformers memorize edges, others that they “stack” edges during search [2].
Most of these studies use simple tasks to probe structural understanding — showing that LLMs partially grasp structure, but not fully.
In our earlier work, though, we found something interesting: when Transformers solve graph tasks, they don’t seem to reason like humans at all.
So we retrained Transformers from scratch on pattern understanding — essentially structure extraction.
But “structure extraction” in LLMs isn’t just “does the graph contain this subgraph?” — the model often needs to generate list of nodes to represent each substructure.
To simplify analysis, we used directed graphs, requiring the model to list all nodes in each target subgraph.
We also minimized textual noise by designing structured inputs:
- Encoder_G(G) → encodes graph topology (neighbor-based (Adjacency List) or edge-based (Edge List))
- Encoder_T → describes the target subgraph (by name or pattern terms)
- Encoder_A → encodes the answer (the actual node list for substrcutres)
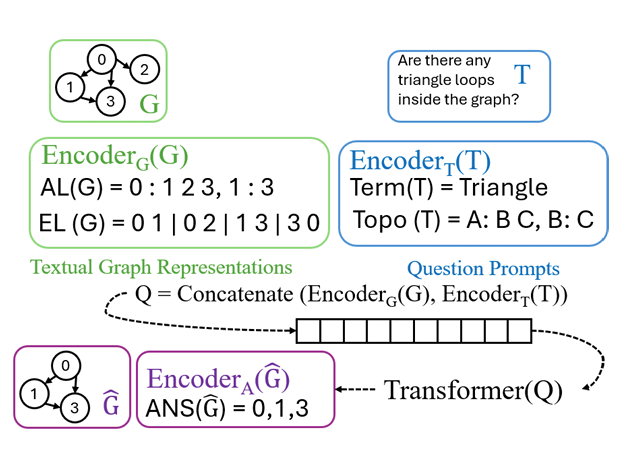 —
—
We broke it down systematically:
- Graphs with one target substructure → solvable
- Graphs with multiple substructures of one type → solvable
- Graphs with multiple substructures of different types → still solvable
Why? Because each Transformer layer behaves like an Intra-Sample Fusion (ISF) process — each layer absorbs at least one node in parallel, merging multiple subgraph signals simultaneously.
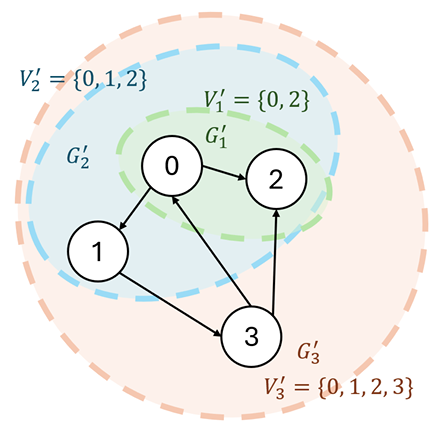
We can even observe this at the last token’s hidden state — the aggregated graph representation:
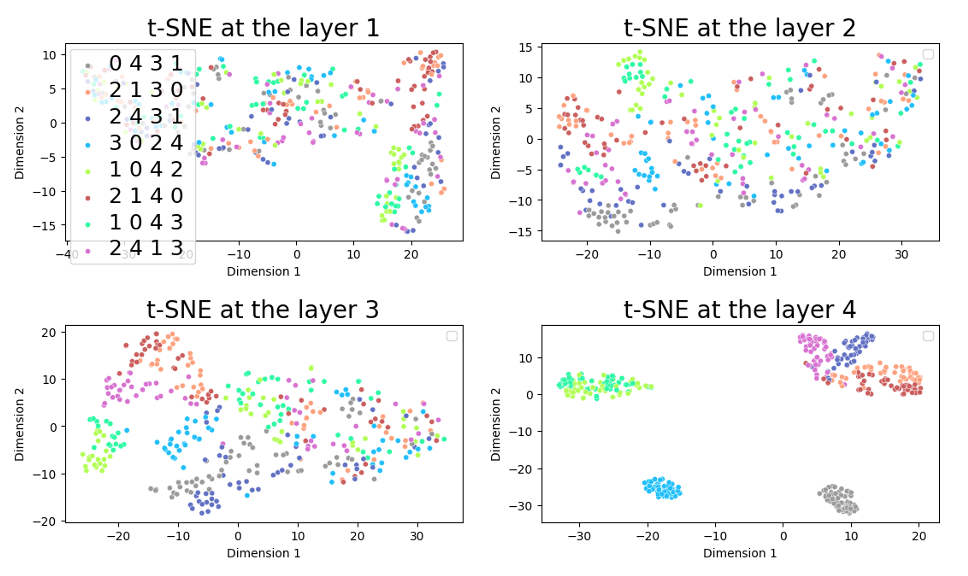
By layer 4, the aggregation of nodes (different colors = different node IDs) becomes clearly visible.
And importantly, we’re looking at the final representation, not embeddings of predicted node IDs — meaning the model already knows the answer before generation.
The node tokens are just a way to unpack that hidden structure.
We also tested this on Llama, generating triangle subgraphs:
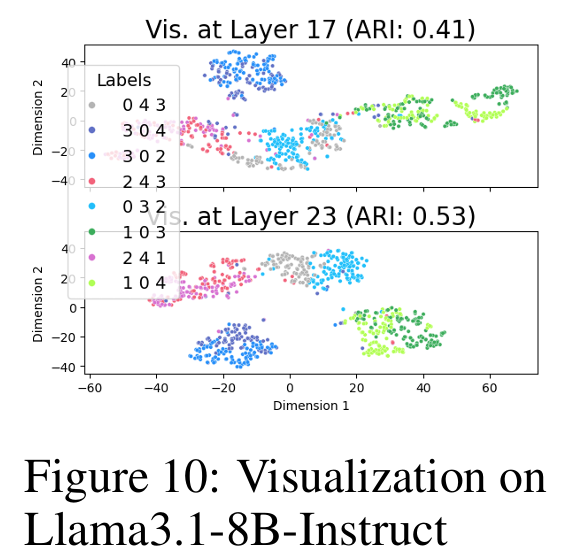
Same story: node aggregation emerges in higher layers.
So — maybe all that “reasoning” and code generation LLMs do? Could just be a performance.
The model already decided where the subgraph is long before it starts “thinking.” in reasoning or coding.
In our previous GraphPatt work, we noticed Transformers often decompose complex subgraphs —
e.g., a “house” shape (triangle + square) is solved by first finding all triangles, then connecting them.
We verified this by training Transformers on decomposed tasks — efficiency shot up.
Essentially, Transformers detect multiple shapes in parallel across subspaces, and combine them into the final structure.

We also tried simple chain-of-thought prompting, but it didn’t help — so maybe pattern-based chains are a more efficient alternative.
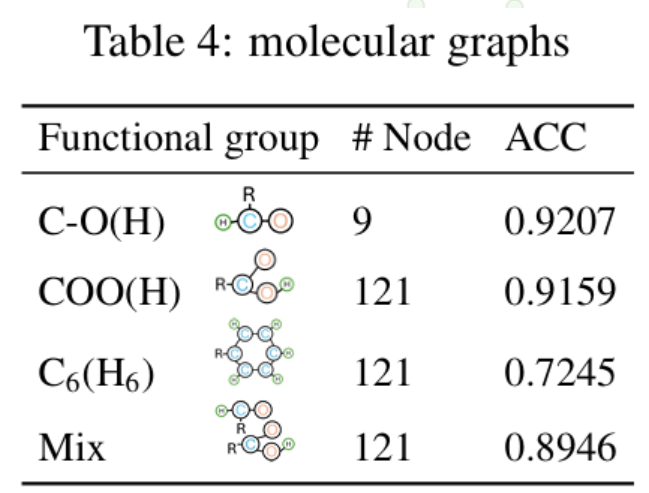
And yes, we tried molecular graphs too — and surprisingly, it worked even better, since molecule graphs are often sparser.
Workshop paper for circuit tracing on graphs
Right in the middle of this, Anthropic dropped
On the Biology of a Large Language Model — a masterpiece on circuit tracing.
We thought: if they’re talking about graphs inside LLMs, how different are those implicit graphs from our explicit input graphs?
Since we’d already studied both path reasoning and pattern extraction, we needed a unified understanding instead of one understanding for one task. Both tasks suggest that LLMs are able to understand the structures, the mechanisms can’t be too different — so we directly applied circuit tracing to graph inputs.
That became our Efficient Reasoning workshop paper.

And the results?
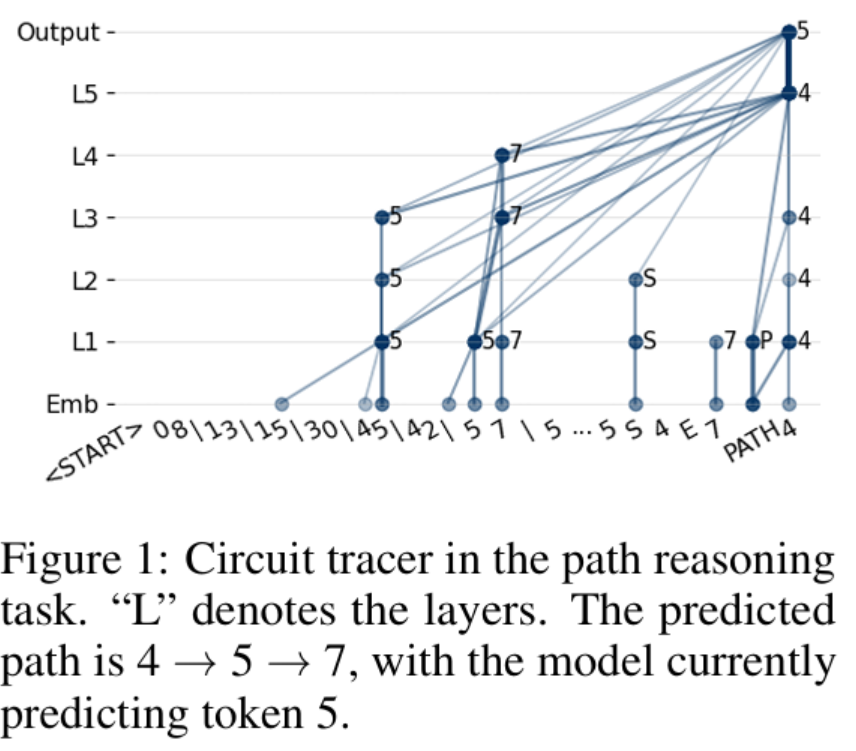
Path reasoning:
Patten extraction
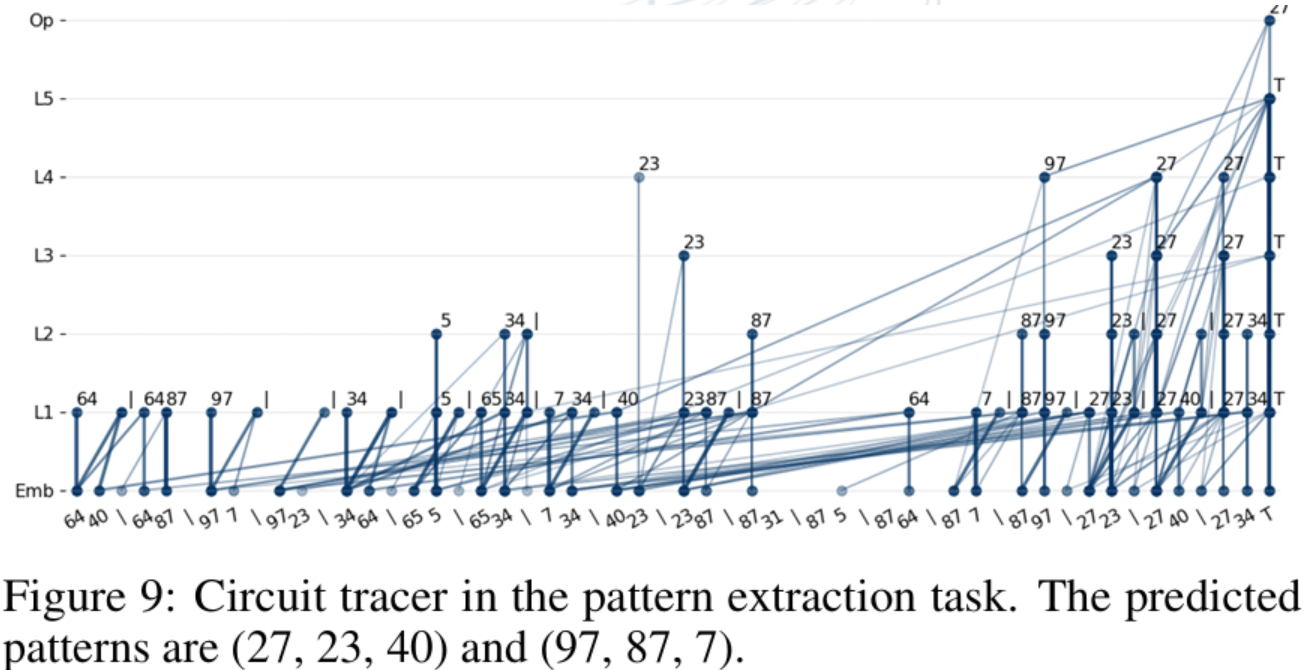
Decoder-only Transformers learn graph structures by token merging — they compress related information directly. For path reasoning, what gets merged are edges. For pattern extraction, it’s node groups forming particular shapes
So edges are basically 2-node patterns, explaining why 2 layers are enough for simple path reasoning.
Then why does it feel hard sometimes? Suggested in precious work, the reason is that next token prediction is affected by graph density [3].
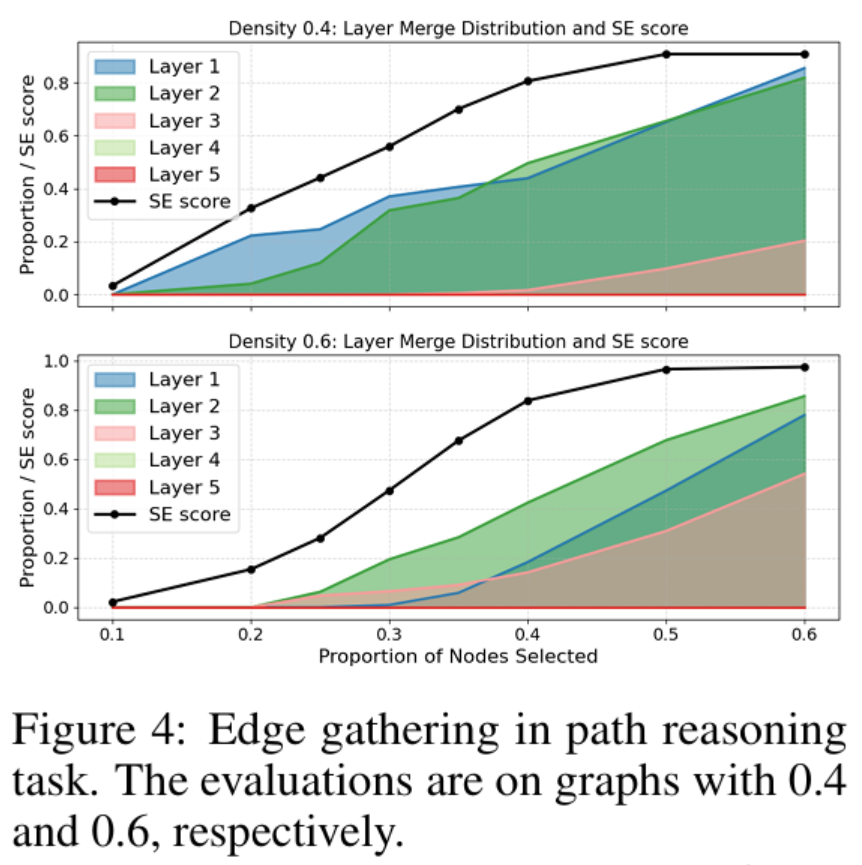
We found that denser graphs push edge aggregation to higher layers meaning layers act like compression units.
If too many next-token candidates exist (i.e., high density), one layer can’t hold all the information,
so more layers are needed.(Compression ratios for future work)
We tried to directly align implicit and explicit graph structures — and failed. So no, Transformer reasoning isn’t human reasoning.
But the implicit graph inside the model is still useful. We can, for example, run degree counting or PageRank on it to find influential neuron nodes, as in GraphGhost [4].
Here’s an interesting case study:

After muting high-degree tokens, Qwen switched to reasoning in Chinese. And yes, people are already running GNNs inside LLMs [5].
Do We Still Need Graph Research in the LLM Era?
Absolutely, graphs are clean, interpretable, and minimal — perfect for testing hypotheses about Transformer mechanisms.
They help us probe ideas like:
Superposition for Chains of continuous thought [6], understanding reinforcement learning dynamics [7] or viewing reasoning steps as graph structures [8]. Although step-wise segmentation isn’t always precise — sometimes specific tokens in higher layers trigger logical shifts — graphs still give us the clearest window into those processes.
And if we believe an LLM’s internals resemble a knowledge graph,
then we can design message-passing mechanisms to make generation more controllable. The cycle continues:
Data driven Deep Learning → Enhance by Structure data (knowledge controlling / GNN) → LLM → Knowledge (again, via RAG… or something next)
🕊️ See you all in San Diego
Reference:
[1]ALPINE: Unveiling The Planning Capability of Autoregressive Learning in Language Models, Neurips 2024
[2]TRANSFORMERS STRUGGLE TO LEARN TO SEARCH, ICLR 2025
[3]The Pitfalls of Next-Token Prediction, ICML 2024
[4]GraphGhost: Tracing Structures Behind Large Language Models, arxiv 2025
[5]Verifying Chain-of-Thought Reasoning via Its Computational Graph, arxiv, 2025
[6]Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought, Neurips 2025
[7] BENEFITS AND PITFALLS OF REINFORCEMENT LEARNING FOR LANGUAGE MODEL PLANNING: A THEORETICAL PERSPECTIVE arxiv, 2025
[8]Topology of Reasoning: Understanding Large Reasoning Models through Reasoning Graph Properties, Neurips 2025
======