
Graph for LLM (3)
Published:
Chinese version is in Zhihu 中文版
Graph for LLM? (III): Explaining Hallucination from a Graph Perspective
The semiannual update is back.
ICML accepted our paper: When Do Hallucinations Arise? A Graph Perspective on the Evolution of Path Reuse and Path Compression. Huge thanks to the two reviewers who both gave initial scores of 5; otherwise I probably would not even have written the rebuttal. Overall, the paper was still a bit rushed, and I feel that some details were not polished as much as they could have been. So I’m genuinely grateful to the reviewers and the AC for being kind.
With this, my first-author papers at the “big three” are finally complete. For now, I can stop grinding papers for the sake of grinding papers and maybe work on something more interesting. Or at least I have found myself an excuse to lie down for a while.
1. A Stream-of-Consciousness Starting Point
Broadly speaking, even I find this paper quite stream-of-consciousness. Some of the ideas were not fully expressed in the paper. If we had written them out too explicitly, we would definitely have been criticized for overclaiming. But since this is a blog post, I still want to discuss some of these loose intuitions. Who knows—maybe one of them can be re-verified later and turned into another paper.
One assumption we make is this:
Suppose every reasoning step is a possible option. Then these steps should be connectable by edges.
If the number of reasoning steps is finite, then we can imagine a graph, where the reasoning process becomes sampling on this graph. Viewing reasoning as graph sampling is probably a natural idea that many people have thought of. Quite a few people may use this perspective to analyze the mechanisms of LLMs, or to improve LLMs with reinforcement-style methods.
But what we want to ask here is slightly different:
If we already know all possible reasoning steps, can an LLM deterministically memorize these reasoning paths during pretraining?
Under this framing, the problem becomes much simpler. We only need to exhaust all paths on this imagined graph to reason about the question.
This is also an advantage of graph-based analysis: once the graph structure is fixed, taking shortest paths allows us to enumerate all optimal reasoning paths. In real-world settings, this is probably impossible, because reasoning paths can always refer to paths from other tasks, and people are still trying to expand the database of available reasoning paths. But with synthetic data, we can jump directly to the idealized setting:
Suppose we already have such a collection of reasoning paths. What kind of behavior would an LLM show?
2. Intrinsic and Extrinsic Reasoning
Following this logic, we divide reasoning into two types.
Intrinsic Reasoning
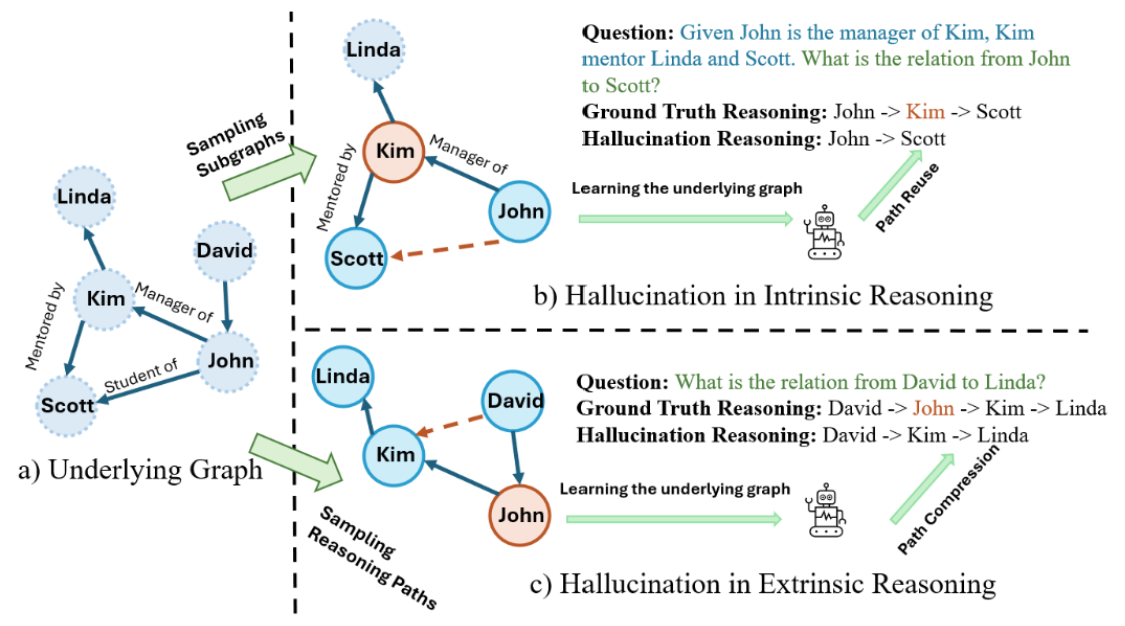
In intrinsic reasoning, the input prompt itself contains some information. If this information is true, then it should belong to the inherent knowledge structure. Here, we call this structure the underlying graph.
Extrinsic Reasoning
In extrinsic reasoning, no additional information is given in the input. The LLM must reason based on its own memory.
We focus on two phenomena:
- The model’s output is inconsistent with the input.
- The model’s output is inconsistent with the underlying knowledge.
From the perspective of sampling on the underlying graph, all paths in extrinsic reasoning can be exhausted. Intrinsic reasoning, in essence, takes a substructure from the underlying knowledge. If we center the analysis around paths, then the substructures containing a given path can also be exhausted.
Under this assumption, we can create a setting where, even with sufficient data, we can analyze why LLMs still hallucinate.
3. Intrinsic Reasoning: Fitting the Underlying Graph First
Take intrinsic reasoning as an example. Our input format is:
1 2 | 2 3 | 3 1 S 1 E 3 PATH 1 2 3
This represents a subgraph composed of nodes 1, 2, and 3. The start node is 1, the end node is 3, and the intermediate path should be:
1 2 3
This path is also the part the model needs to predict during testing.
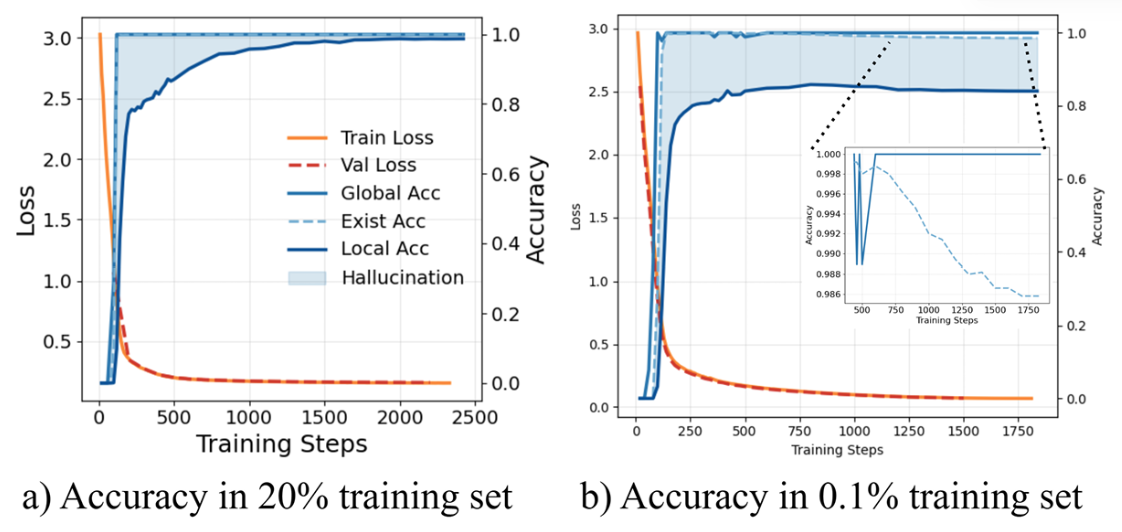
When we train a transformer on data like this, we find that before the transformer can answer these samples accurately, the first thing it does is actually fit the underlying graph rather than memorize individual samples.
In the figure below, the blue curve at the top means that the path predicted by the model can be justified by the underlying graph. At this stage, however, the prediction accuracy on individual samples is still not high. This corresponds to the blue-shaded region in the figure. When the dataset is too small, this phenomenon becomes even more obvious.
A Side Note on Path Search
Some previous work has discussed how difficult it is for transformers to search for paths on a specified structure. When the given conditional graph becomes very large, the model may no longer work reliably.
But based on our analysis, we can now make a bold guess:
If the given conditional graph is very large, does that mean the corresponding underlying graph should also be very large?
And under such a huge underlying graph, how many subgraphs can we actually sample?
If the subgraphs are generated randomly, then surely we will get far fewer of them than through exhaustive sampling. In that case, this should probably be considered an incomplete-dataset scenario.
4. Extrinsic Reasoning: Path Reuse and Path Compression
On the other hand, if we sample enough paths, can the model truly understand the structure of the underlying graph?
Here, our input format becomes:
S 1 E 3 PATH 1 2 3
In the test set, we only provide the start node and the end node, and ask the model to infer from memory what the path should be.
Of course, in the data design, path reuse is impossible by construction. The model can only use known edges from the training set and combine them into new paths.
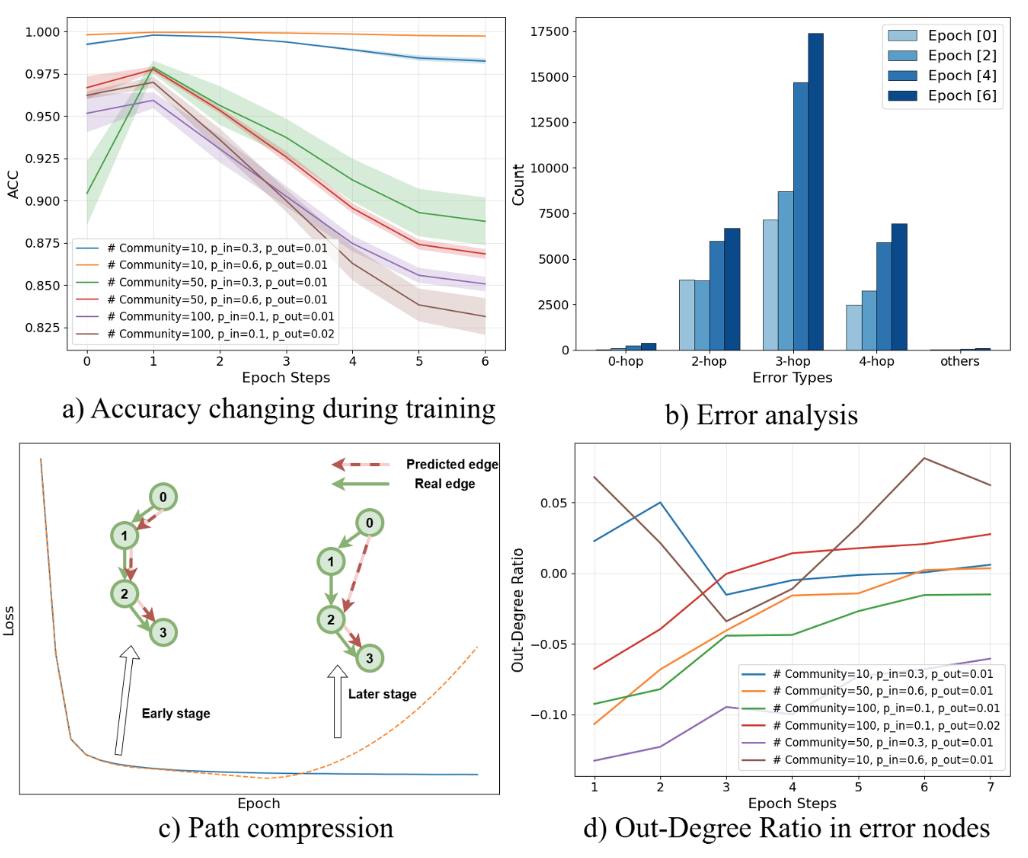
Training a transformer on this data reveals another phenomenon: in the later stages of training, the model exhibits path compression. That is, it starts treating a two-hop node as if it were a one-hop neighbor. This is accompanied by a drop in accuracy.
To give an analogy, suppose the original logic is:
A pigeon’s good friend is a kestrel.
The kestrel eats a spotted dove.
After compression, the logic may become:
The pigeon eats the spotted dove.
This is clearly inconsistent with the facts.
We also find that path compression often happens around nodes with high out-degree. One possible explanation is that these high-out-degree nodes are repeatedly sampled, eventually causing the model to ignore intermediate nodes.
In addition, this phenomenon is closely related to the properties of the underlying graph itself. For example, if the graph has stronger community structure, then perhaps some parts of the data do not have such differentiated in-degree and out-degree relationships, and path compression caused by sampling may become much less severe.
In fact, this suggests something interesting. People used to say that graph size is a bottleneck for LLMs in understanding graph structure. But now it seems that the bottleneck may not be size itself. Instead, it may be the properties of the graph: its density, connectivity, and structural form.
5. From Synthetic Graphs to Real-World Text
In real data, there is usually all kinds of noise. Human wording contains many irrelevant tokens mixed into the important information. So in real-world settings, what we often observe is that the model has very low loss, but what it says still does not follow the intended logic.
Our model may provide one possible explanation for this.
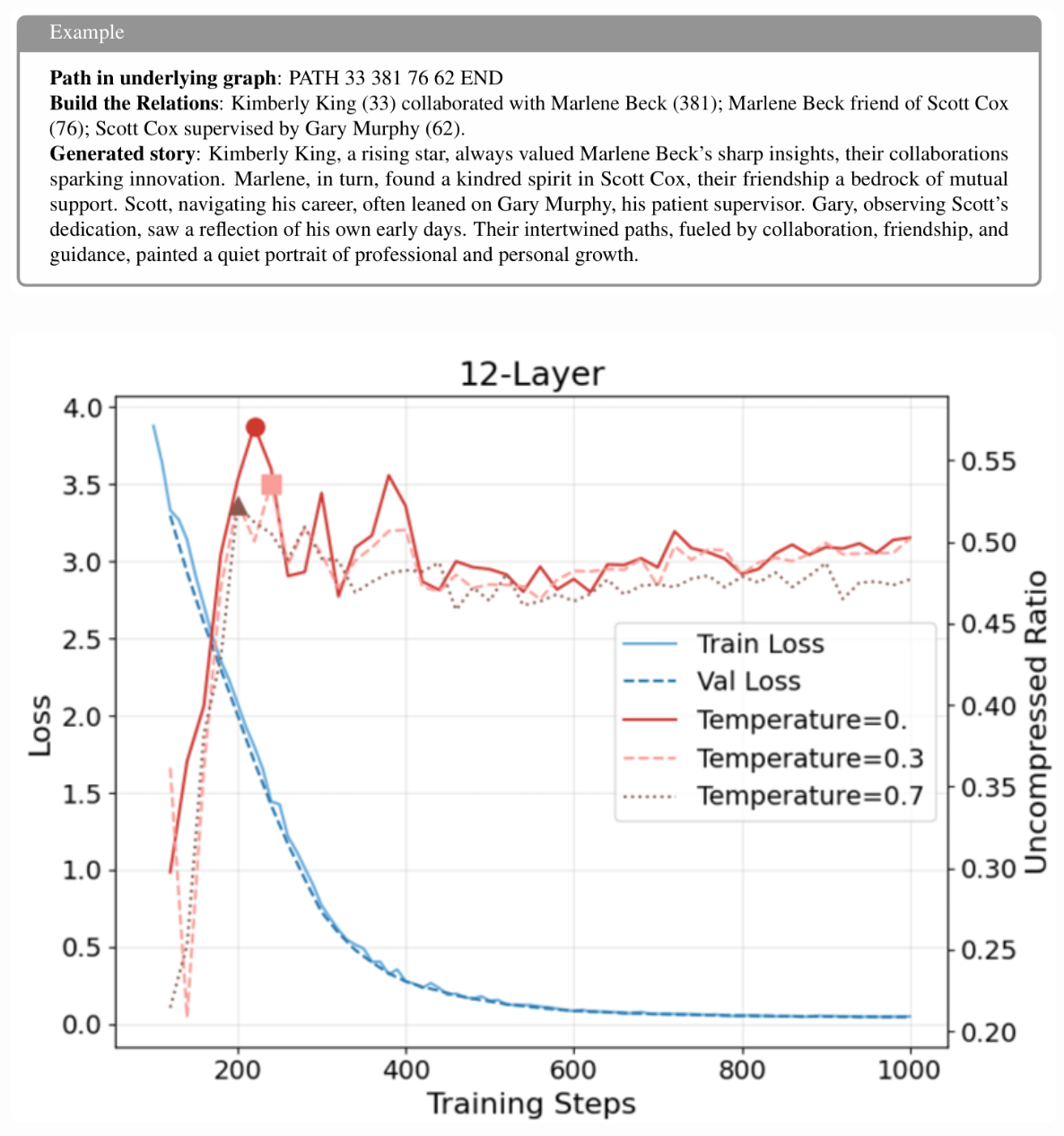
For example, suppose these intermediate nodes are all entity nodes, and we use them to define relationships between entities. Then we ask Gemini to generate short stories based on these relationships. In this way, we can ask:
In a real storytelling setting, how many logical facts can the model actually remember?
The experiment shows that the point at which the model remembers the largest number of logical facts is not when the loss is lowest. Instead, it happens at a relatively early stage of training. This fits our previous hypothesis quite well.
The design of this experiment was inspired by Professor Zhu Zeyuan’s synthetic-data methodology in Physics of Language Models. When I was at NeurIPS, I talked with a senior researcher from Meta about the phenomena we found on graphs and how we might extend them to the real world. He suggested that I go back and look at Zhu’s method. I did, and it turned out to be exactly what we needed.
Much appreciated.
6. Extensions: Reversal Curse and Other Behaviors
There are also some possible extensions worth discussing.
Path compression may indeed be a real form of hallucination. But in some cases, human observers may not interpret it as hallucination.
For example, consider the Reversal Curse: sometimes we say that an LLM knows the reasoning from A to B, but not from B to A. Under our model, this seems somewhat understandable.
Suppose the reasoning chain that actually exists in the dataset is:
A -> B -> C -> A
In the early stage, the model needs C to connect the reasoning path. Only in the later stage can path compression possibly produce something like:
A -> B -> A
In other words, if we have this graph-based model, we can construct many different scenarios to understand potential behaviors of LLMs. These experiments can basically be run on a single GPU and do not require much compute, so they are quite suitable for toy examples.
7. Related Work
There are already quite a few papers that use graphs to model certain scenarios and analyze LLM capabilities. Here are some examples:
- Alpine: Unveiling the Planning Capability of Autoregressive Learning in Language Models — NeurIPS 2024
- The Pitfalls of Next-Token Prediction — ICML 2024
- Benefits and Pitfalls of Reinforcement Learning for Language Model Planning: A Theoretical Perspective — ICLR 2026
- Transformers Struggle to Learn to Search — ICLR 2025
- Deep Sequence Models Tend to Memorize Geometrically; It Is Unclear Why
- Emergence of Superposition: Unveiling the Training Dynamics of Chain of Continuous Thought — ICLR 2026
- Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought — NeurIPS 2025
8. Why Graphs Are Useful for Synthetic Data
Because graph structures are simple to construct, they are very convenient for building synthetic scenarios. Of course, what we have done is still far from complete.
From the data perspective, we still need to discuss what kinds of data correspond to what kinds of geometric constructions. For example, in social graphs, we may talk about some nodes belonging to certain communities. In language, it is also possible that some words belong to certain corpora or semantic domains.
In our previous discussion, we mentioned that path compression may be related to community structure. Then in real corpora, will there also be a similar gap?
Another direction is mechanistic research on transformers. Once the data is simplified, studying the model’s mechanisms should also become easier. Previously, we also discussed that LLMs themselves may contain certain graph structures. How the structure of the source data aligns with the internal structure of LLMs is also worth discussing.
Overall, these directions may not sound as fancy as agents or similar topics. But it may still be worth thinking about how to model those fancy settings through this lens.
9. Closing: Wide Blue Skies
Finally, one more whisper.
Since Ace Combat 8 is coming soon, I have recently been revisiting Ace Combat 7. There is one line that feels very fitting for the assumption of this paper:
Everything is bound to change, wide blue skies always the same.
The information contained in the data itself is fixed. Human knowledge, under these texts, is also fixed. What changes are only the sampling process and the training time.
So the question becomes:
When can the transformer, as a container, fully and deterministically store human knowledge?
My coauthor will probably attend ICML. As for me, I will be making my second pilgrimage to ACL in San Diego. I will also be in San Jose over the summer, so feel free to reach out. I would be very happy to discuss with anyone who can carry me forward.
Much appreciated.